ヒンディー語PDFをWordに変換 – 無料オンライン
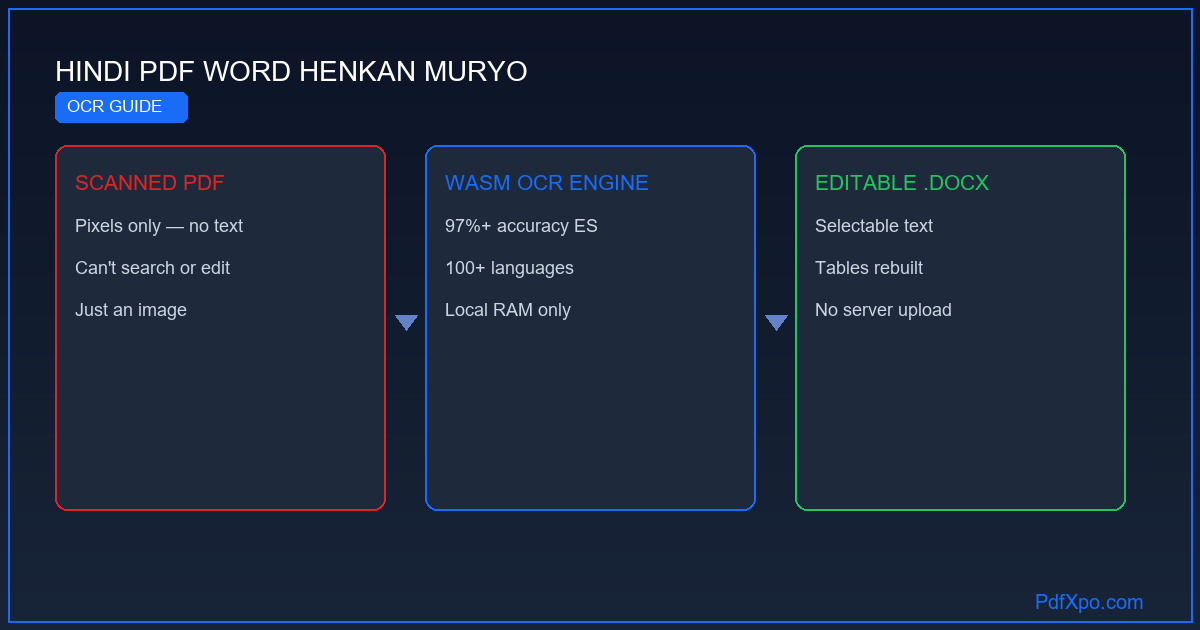
スキャンか原本か:OCRがすべてを変える理由
スキャンしたPDFをWordに変換するのは、原本のPDFを変換するより技術的にずっと難しいものです。理由は単純で、スキャンしたPDFにはテキストデータがまったくありません——ページの写真の集まりです。スキャン上の「請求書」という語は「請」「求」…の文字ではなく、その文字のように見える画素の塊です。文書を編集可能にするには、画像を解析して本当のテキストを再構成する光学文字認識(OCR)が必要です。PdfXpoは無料・無制限の高度なOCRエンジンを内蔵します。
PdfXpoのOCRの仕組み:4段階
段階1 — 画像の前処理
各ページを同じ解像度に整え、コントラストを高め、背景ノイズを減らし、スキャンの傾きを補正します。斜めにスキャンされた文書は自動でまっすぐにされます。
段階2 — 領域の識別
ページをテキストブロック、画像、表の領域に分割します。各領域を別々に処理し、画像の説明文が隣の段落と混ざらないようにします。
段階3 — 文字認識
各テキスト領域で、機械学習モデルが各グリフの形を解析し、正しいUnicode文字に対応づけます。このモデルは100以上の言語の数百万ページで学習されています。
段階4 — テキストの再構成
認識された文字を語に、語を行に、行を段落に組み立てます——文書の元の構造を保ちながら。
文書の種類別の精度
標準フォント(游明朝、ヒラギノ、メイリオ)の日本語テキストを最低300 DPIでスキャンすると、PdfXpoは97%超の精度に達します——つまり1,000語に2〜3語ほど不完全になりうる程度です。より難しい場合:
- 手書き文書 : 筆跡により50〜80%(OCRは印刷文字に最適化)。
- 古い文書(1950年以前)の薄れたインク : 60〜85%。
- 色や模様のある背景 : 70〜90%。
- 非常に小さい文字(8pt未満) : 精度が低下。
アラビア語・ヒンディー語など非ラテン文字
アラビア文字やデーヴァナーガリー(ヒンディー語)のPDFは特別な処理が要ります。アラビア語 : PdfXpoは右から左(RTL)の書字方向を自動で検出し、正しい向きのWord文書を作ります。アラビア文字は位置により異なるつながり方をするため、モデルはこの結合規則で学習されています。ヒンディー語/デーヴァナーガリー : この文字は文字の上の線(「マートラー」)と文字間の合字があり、鮮明な印刷文書で95%超の精度で認識されます。
最低要件とスキャンの準備
- 解像度 : 最低200 DPI、最良の画質は300 DPI。150 DPI未満では文字がぼやけます。
- コントラスト : 白地に黒い文字が最良の結果を与えます。
- 傾き : 約5°までのスキャンは自動補正され、それ以上は変換前に手でまっすぐにしてください。
携帯でスキャンするならMicrosoft LensやAdobe Scan(無料)を使ってください。これらは遠近を補正し、コントラストを最適化して、きれいなPDFに書き出します——OCRに理想的な元データです。
文字が認識されると、PdfXpoは構造を再構成します——段落、見出し、さらにはスキャンした表までWordのネイティブ表として描き直します。OCRはWebAssemblyでローカル実行されます。多くの場合機密であるスキャン文書が決して送信されない一方、SmallpdfやAdobeはOCRをクラウドの有料プランに置いています。
技術的な背景:PDFをWordに変換するのがなぜこれほど難しいのか
PDF形式は1993年にAdobeが、編集の観点から根本的な制約とともに作りました。PDFは構造化された文書ではなく、描画命令の集合を保存します。あらゆる要素——あらゆる文字、あらゆる線、あらゆる画像——がページ上で絶対座標(x, y)を持ちます。「契約」という語は一つの語ではなく、それぞれ位置・色・フォントを持つ二つの字のグリフです。
この構造はPDFを印刷と表示に理想的にしますが、変換には厄介にします。「段落」構造も、「表」メタデータも、「見出し」階層もありません。表や見出しに見えるものは、幾何的な解析で再構成しなければなりません。
PdfXpoの4段階アーキテクチャ
段階1 — PDFオブジェクトの完全な抽出 : パーサがファイルの各コンテンツストリームを読み、すべてのテキストオブジェクトを完全な属性とともに抽出します。座標、フォント名、サイズ、字間、色。同時にグラフィックオブジェクト(線、矩形、パス)を認識し、画像を色プロファイルとともに抽出します。
段階2 — 構造的な分割 : アルゴリズムがテキストオブジェクトを空間的な近さと組版の特徴により論理ブロックにまとめます。見出しはより大きいフォント、より広い間隔、位置で認識されます。表は交わって格子を作る線分から、多段レイアウトは段間の横の区切りから検出されます。
段階3 — 意味の対応づけ : 各構造ブロックがWord要素に対応づけられます。見出し → 見出し1/2/3スタイル、リスト項目 → 番号付き・箇条書きのWordリスト、表 → ネイティブな表オブジェクト、脚注 → 正しく結ばれたOOXML注オブジェクト、画像 → 固定された画像オブジェクト。
段階4 — OOXML文書の生成 : OOXML規格(ISO/IEC 29500)に合う.docxファイルが生成されます。ページ寸法、余白、ヘッダー、フッターが原本から引き継がれます。ないフォントは計量的に同等のフォントに置き換えられます。
計測値:PdfXpoが保証するもの
PdfXpoと代替の比較
決定的な違い : PdfXpoはいかなるファイルデータもサーバーに送りません。Adobe、Smallpdf、iLovePDFでは文書が端末を離れます——機密の業務・個人文書にとって重要な法的現実です。
手順:PdfXpoでPDFをWordに変換する
ステップ1 — ブラウザを開く : Chrome、Edge、Firefox、Safariで[pdfxpo.com/pdf-to-word](/pdf-to-word)にアクセスします。インストールなし、アカウントなし、拡張機能なし。
ステップ2 — ファイルを読み込む : PDFをアップロード領域へドラッグするか「ファイルを選択」をクリックします。200MBまで、一日の制限なし。
ステップ3 — 変換を待つ : 処理はローカルで動きます。10ページ : 5〜15秒。50ページ : 20〜40秒。200ページ : 1〜3分。スキャンのページ(OCR) : 2〜4倍。
ステップ4 — ダウンロードして開く : .docxがダウンロードに保存されます。Microsoft Word 2010以降、LibreOffice Writer、Google Docsで開きます。
プライバシー:技術的に検証できる保証
WebAssemblyは、ネイティブコードを隔離されたサンドボックスで実行するブラウザ内の実行環境です。PdfXpoの変換アルゴリズムはブラウザのメモリ内でWebAssemblyモジュールとして直接動きます——サーバーは一切関与しません。
30秒の検証 : 開発者ツール(F12)を開き、「ネットワーク」タブでPdfXpoにPDFを読み込みます。変換中にスクリプトとスタイルシートの読み込みは見えますが、ファイルの内容を運ぶHTTP通信はありません。技術的な証拠です。ファイルはブラウザを離れません。
PDFをWordに変換すべきとき
変換の必要は、数多くの日常の場面で生まれます。PDFで契約書や書簡を受け取り、署名前に一つの条項を変える必要があります。PDFでしかないひな形——履歴書、提案書、報告書——を一から書かずに再利用したい。先生が講義資料をPDFで共有し、引用をノートに写したい。チームがデータを業務文書に入れる必要のあるPDF報告書を送ってくる。こうしたすべての場合、Wordに変換すれば入れ直すのに比べ何時間も節約でき、表・画像・レイアウトも崩さずに保てます。PdfXpoはこの手順を速く、無料で、機密にします——文書をどこにも送らずに。
あらゆるワープロと互換
生成された.docxファイルはOOXML規格に従い、Microsoft Word(2010以降)、LibreOffice Writer、Google Docs、Apple Pages(読み込み)で問題なく開きます。WindowsとMacはもちろん、Linux、Android、iOSでも。一つのソフトに縛られません。最も都合の良い場所で編集し、終わったら再びPDFに書き出します。変換が登録やインストールを求めないので、流れ——開く、変換する、編集する——は最初から最後まで数秒で済みます。
ローカル処理がプライバシーだけでなく速度も意味する理由
PdfXpoが「ファイルは端末を離れない」と言うのは標語ではなく、WebAssembly利用の直接の結果です。WebAssembly技術はPDF処理のコード(C++やRustで書かれた)をブラウザのJavaScriptエンジンで直接実行します。ファイルを送るAPIも、受け取るサーバーもありません。ここには速度という実用的な利点もあります。クラウドツールではファイルがまずサーバーにアップロードされ、そこで処理され、再びダウンロードされます。この三段階は、特に大きなファイルや遅い回線では数分かかることがあります。PdfXpoではアップロードとダウンロードの段階が完全になくなり、変換がファイルのある場所、つまり端末のメモリ内で始まります。その結果、より私的でありながら多くの場合より速い体験が得られます。銀行明細、契約書、医療書類、公的書類のような機密内容にとって、これは欠かせない保証です。
最良の変換結果のためのヒント
最良の結果のために、スキャンよりソフトで作った原本のPDFを優先してください。忠実度が最高です。文書がスキャンなら最低200 DPIでスキャンし、OCRが各文字を正しく認識するよう均一な照明に気を付けてください。多段の文書は変換後に段の順を確認し、非常にグラフィカルなレイアウトはわずかな手作業の調整が要ることがあります。最後に、大きなファイルを処理する間はタブを開いたままにしてください。変換はローカルで進み、ページを閉じると作業が止まります。.docxを受け取ったら、使う前に素早く目を通して書式を確かめてください。こうした小さな習慣が、契約書でも履歴書でも学術論文でも、ほぼあらゆる文書で完璧に近い結果を与えます。さらに、変換が完全にブラウザで行われるため、同じ文書を会社のパソコン、自宅のノート、移動中の携帯など複数の端末で、何も入れずに再び処理できます。必要なのは最新のブラウザと数秒の時間だけで、利用回数に制限がない点が実務で大きな差を生みます。
登録なし。透かしなし。ファイル制限なし。クラウドへのアップロードなし。
100% Local Privacy
Your files never leave your computer
Local Browser Power
Instant Processing in Browser
Secure Client-Side Processing
Data is handled entirely within your browser for maximum security
How to ヒンディー語PDFをWordに変換 – 無料オンライン — Step by Step
なぜPdfXpoか?
PdfXpoはWebAssembly技術を使います – ファイルがブラウザ内で直接処理され、サーバー送信がありません。100%無料、無制限、登録なし。
Common Questions
PdfXpoでスキャンしたPDFをWordに変換できますか?
はい。PdfXpoはスキャン画像を解析して文字を認識し、編集可能なWord文書を作るOCRエンジンを内蔵します。最低200 DPIの鮮明なスキャンで認識率が95%を超えます。
OCRはどの言語を認識しますか?
日本語、英語、スペイン語、ドイツ語、アラビア語、ヒンディー語を含む30以上の言語。エンジンは印刷文字に最適化されており、手書き文書は精度が下がります。
最良のOCR結果をどう得ますか?
ページを撮影する代わりに200〜300 DPIでスキャンし、影や波打つページを避けてください。鮮明でコントラストの良いスキャンがはるかに優れた認識を与えます。
スキャンした表も再構成されますか?
はい。OCRと組み合わせて、PdfXpoはスキャンした表の各セルの文字を認識し、構造をネイティブなWord表として、列の整列を保ちながら再構成します。
私のスキャン文書はOCRのために送られますか?
いいえ。OCRはWebAssemblyでローカルに動きます。多くの場合機密であるスキャン文書がサーバーに送られることは決してありません。OCRをクラウドの有料プランに置くサービスとは異なります。