अरबी PDF को Word में बदलें – मुफ़्त
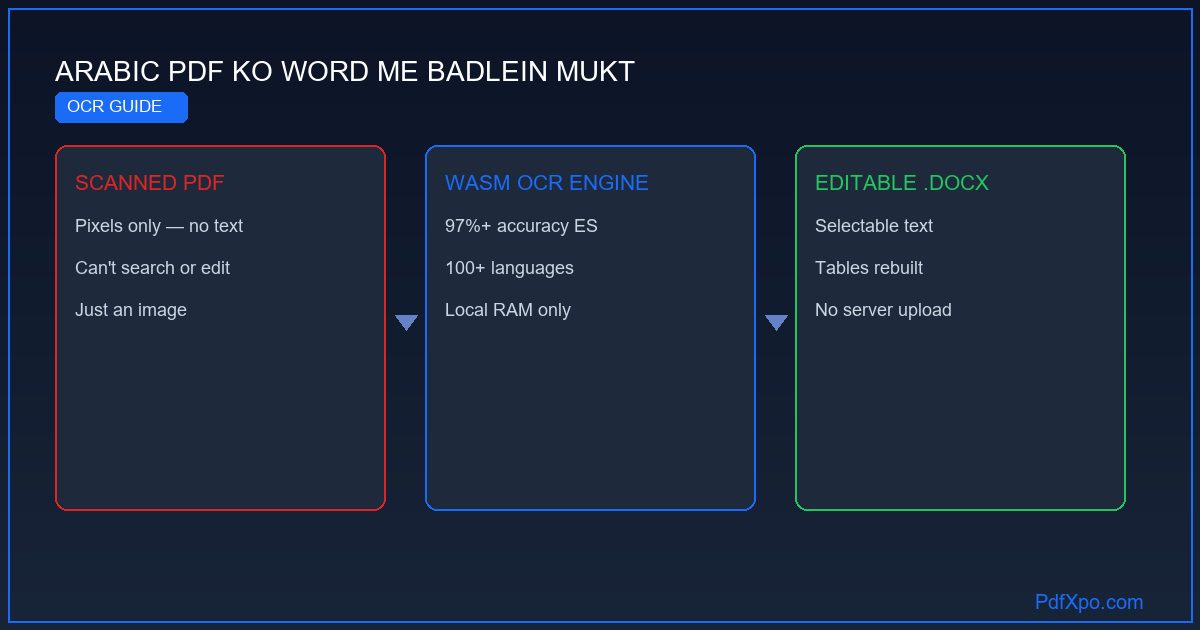
स्कैन या मूल: OCR सब कुछ क्यों बदल देता है
स्कैन की गई PDF को Word में बदलना मूल PDF बदलने की तुलना में तकनीकी रूप से कहीं ज़्यादा कठिन है। कारण सीधा है: स्कैन की गई PDF में कोई टेक्स्ट डेटा होता ही नहीं — यह पेज की तस्वीरों का संग्रह है। स्कैन पर लिखा "इनवॉइस" शब्द अक्षरों का समूह नहीं, बल्कि उन अक्षरों जैसे दिखने वाले पिक्सेल का झुंड होता है। दस्तावेज़ को एडिटेबल बनाने के लिए ऑप्टिकल कैरेक्टर रिकग्निशन (OCR) चाहिए, जो इमेज का विश्लेषण करके असली टेक्स्ट पुनर्निर्मित करता है। PdfXpo में मुफ़्त और असीमित उन्नत OCR इंजन अंतर्निहित है।
PdfXpo का OCR कैसे काम करता है: 4 चरण
चरण 1 — इमेज का पूर्व-प्रसंस्करण
हर पेज को एक ही रिज़ॉल्यूशन पर लाया जाता है, कंट्रास्ट बढ़ाया जाता है, बैकग्राउंड शोर घटाया जाता है, और स्कैन का झुकाव ठीक किया जाता है। तिरछा स्कैन किया गया दस्तावेज़ अपने-आप सीधा कर दिया जाता है।
चरण 2 — क्षेत्रों की पहचान
पेज को टेक्स्ट ब्लॉक, इमेज और टेबल क्षेत्रों में बाँटा जाता है। हर क्षेत्र को अलग प्रोसेस किया जाता है ताकि इमेज का कैप्शन बग़ल के पैराग्राफ़ से न मिल जाए।
चरण 3 — अक्षर पहचान
हर टेक्स्ट क्षेत्र में मशीन लर्निंग मॉडल हर ग्लिफ़ के आकार का विश्लेषण करके उसे सही यूनिकोड अक्षर से जोड़ता है। यह मॉडल 100 से अधिक भाषाओं के लाखों पेज पर प्रशिक्षित है।
चरण 4 — टेक्स्ट का पुनर्निर्माण
पहचाने गए अक्षरों को शब्दों में, शब्दों को पंक्तियों में और पंक्तियों को पैराग्राफ़ में जोड़ा जाता है — दस्तावेज़ की मूल संरचना बनाए रखते हुए।
दस्तावेज़ के प्रकार के अनुसार सटीकता
मानक फ़ॉन्ट में कम से कम 300 DPI पर स्कैन किए गए अंग्रेज़ी या हिंदी टेक्स्ट पर PdfXpo 97% से अधिक सटीकता तक पहुँचता है — यानी प्रति 1,000 शब्दों में लगभग 2–3 शब्द अधूरे रह सकते हैं। कठिन स्थितियों में:
- हस्तलिखित दस्तावेज़ : लिखावट के अनुसार 50–80% (OCR मुद्रित अक्षरों के लिए अनुकूलित है)।
- पुराने दस्तावेज़ (1950 से पहले) की फीकी स्याही : 60–85%।
- रंगीन या पैटर्न वाला बैकग्राउंड : 70–90%।
- बहुत छोटे अक्षर (8pt से कम) : सटीकता घट जाती है।
हिंदी, अरबी और अन्य ग़ैर-लैटिन लिपियाँ
देवनागरी (हिंदी) और अरबी लिपि की PDF को विशेष प्रसंस्करण की ज़रूरत होती है। हिंदी/देवनागरी : इस लिपि में अक्षरों के ऊपर एक रेखा (शिरोरेखा या "मात्रा" वाली) और अक्षरों के बीच संयुक्ताक्षर होते हैं; स्पष्ट मुद्रित दस्तावेज़ों में इन्हें 95% से अधिक सटीकता से पहचाना जाता है। अरबी : PdfXpo दाएँ-से-बाएँ (RTL) लेखन दिशा अपने-आप पहचानता है और सही दिशा वाला Word दस्तावेज़ बनाता है। चूँकि अरबी अक्षर स्थिति के अनुसार अलग-अलग जुड़ते हैं, मॉडल इन संयोजन नियमों पर प्रशिक्षित है।
न्यूनतम आवश्यकताएँ और स्कैन की तैयारी
- रिज़ॉल्यूशन : कम से कम 200 DPI, सर्वोत्तम गुणवत्ता के लिए 300 DPI। 150 DPI से कम पर अक्षर धुंधले हो जाते हैं।
- कंट्रास्ट : सफ़ेद पृष्ठभूमि पर काला टेक्स्ट सबसे अच्छा परिणाम देता है।
- झुकाव : लगभग 5° तक के स्कैन अपने-आप ठीक हो जाते हैं; उससे ज़्यादा होने पर बदलने से पहले हाथ से सीधा कर लें।
मोबाइल से स्कैन करना हो तो Microsoft Lens या Adobe Scan (मुफ़्त) इस्तेमाल करें। ये परिप्रेक्ष्य ठीक करते हैं, कंट्रास्ट अनुकूलित करते हैं और साफ़ PDF निर्यात करते हैं — OCR के लिए आदर्श कच्चा माल।
अक्षर पहचाने जाने के बाद PdfXpo संरचना पुनर्निर्मित करता है — पैराग्राफ़, शीर्षक, और यहाँ तक कि स्कैन की गई टेबल भी Word की मूल टेबल के रूप में फिर से बनाई जाती है। OCR WebAssembly से लोकल चलता है, इसलिए अक्सर संवेदनशील रहने वाले स्कैन दस्तावेज़ कभी नहीं भेजे जाते, जबकि Smallpdf और Adobe OCR को क्लाउड के सशुल्क प्लान में रखते हैं।
तकनीकी पृष्ठभूमि: PDF को Word में बदलना इतना कठिन क्यों है
PDF फ़ॉर्मेट को Adobe ने 1993 में बनाया था, संपादन के नज़रिए से एक बुनियादी सीमा के साथ। PDF कोई संरचित दस्तावेज़ नहीं, बल्कि ड्रॉइंग निर्देशों का संग्रह सहेजता है। हर तत्व — हर अक्षर, हर रेखा, हर इमेज — का पेज पर निरपेक्ष निर्देशांक (x, y) होता है। "अनुबंध" शब्द एक शब्द नहीं, बल्कि अलग-अलग स्थिति, रंग और फ़ॉन्ट वाले अक्षर-ग्लिफ़ का समूह है।
यह संरचना PDF को प्रिंट और प्रदर्शन के लिए आदर्श बनाती है, पर कन्वर्ज़न के लिए मुश्किल। न कोई "पैराग्राफ़" संरचना है, न "टेबल" मेटाडेटा, न "शीर्षक" पदानुक्रम। जो टेबल या शीर्षक जैसा दिखता है, उसे ज्यामितीय विश्लेषण से पुनर्निर्मित करना पड़ता है।
PdfXpo की 4-चरणीय संरचना
चरण 1 — PDF ऑब्जेक्ट का पूर्ण निष्कर्षण : पार्सर फ़ाइल की हर कंटेंट स्ट्रीम पढ़ता है और सभी टेक्स्ट ऑब्जेक्ट को पूरी विशेषताओं सहित निकालता है — निर्देशांक, फ़ॉन्ट नाम, साइज़, अक्षर-अंतराल, रंग। साथ ही ग्राफ़िक ऑब्जेक्ट (रेखाएँ, आयत, पथ) पहचानता है और इमेज को कलर प्रोफ़ाइल सहित निकालता है।
चरण 2 — संरचनात्मक विभाजन : एल्गोरिदम टेक्स्ट ऑब्जेक्ट को स्थानिक निकटता और टाइपोग्राफ़िक विशेषताओं के आधार पर तार्किक ब्लॉक में जोड़ता है। शीर्षक बड़े फ़ॉन्ट, अधिक अंतराल और स्थिति से पहचाने जाते हैं। टेबल उन रेखाखंडों से पहचानी जाती है जो मिलकर ग्रिड बनाते हैं, और बहु-कॉलम लेआउट कॉलमों के बीच के क्षैतिज विभाजक से।
चरण 3 — अर्थ का मिलान : हर संरचनात्मक ब्लॉक को Word तत्व से जोड़ा जाता है। शीर्षक → Heading 1/2/3 स्टाइल, सूची-आइटम → क्रमांकित/बुलेट Word सूची, टेबल → मूल टेबल ऑब्जेक्ट, फ़ुटनोट → सही ढंग से जुड़े OOXML नोट ऑब्जेक्ट, इमेज → स्थिर इमेज ऑब्जेक्ट।
चरण 4 — OOXML दस्तावेज़ का निर्माण : OOXML मानक (ISO/IEC 29500) के अनुरूप .docx फ़ाइल बनती है। पेज के आयाम, मार्जिन, हेडर और फ़ुटर मूल से लिए जाते हैं। उपलब्ध न होने वाले फ़ॉन्ट मापीय रूप से समकक्ष फ़ॉन्ट से बदले जाते हैं।
मापे गए आँकड़े: PdfXpo क्या गारंटी देता है
PdfXpo और विकल्पों की तुलना
निर्णायक अंतर : PdfXpo कोई भी फ़ाइल डेटा सर्वर पर नहीं भेजता। Adobe, Smallpdf और iLovePDF में दस्तावेज़ आपके डिवाइस से बाहर जाता है — संवेदनशील ऑफ़िस और निजी दस्तावेज़ों के लिए यह एक अहम क़ानूनी वास्तविकता है।
तरीका: PdfXpo से PDF को Word में बदलें
चरण 1 — ब्राउज़र खोलें : Chrome, Edge, Firefox या Safari में pdfxpo.com/pdf-to-word पर जाएँ। कोई इंस्टॉल नहीं, कोई अकाउंट नहीं, कोई एक्सटेंशन नहीं।
चरण 2 — फ़ाइल लोड करें : PDF को अपलोड क्षेत्र में खींचें या "फ़ाइल चुनें" पर क्लिक करें। 200MB तक, कोई दैनिक सीमा नहीं।
चरण 3 — कन्वर्ज़न की प्रतीक्षा करें : प्रोसेसिंग लोकल चलती है। 10 पेज : 5–15 सेकंड। 50 पेज : 20–40 सेकंड। 200 पेज : 1–3 मिनट। स्कैन वाले पेज (OCR) : 2–4 गुना।
चरण 4 — डाउनलोड करके खोलें : .docx डाउनलोड में सहेजी जाती है। Microsoft Word 2010 या नया, LibreOffice Writer, या Google Docs में खोलें।
गोपनीयता: तकनीकी रूप से सत्यापन योग्य गारंटी
WebAssembly ब्राउज़र के अंदर एक निष्पादन परिवेश है जो नेटिव कोड को एक अलग सैंडबॉक्स में चलाता है। PdfXpo का कन्वर्ज़न एल्गोरिदम ब्राउज़र की मेमोरी में WebAssembly मॉड्यूल के रूप में सीधे चलता है — कोई सर्वर शामिल नहीं।
30 सेकंड का सत्यापन : डेवलपर टूल्स (F12) खोलें, "नेटवर्क" टैब में PdfXpo पर PDF लोड करें। कन्वर्ज़न के दौरान स्क्रिप्ट और स्टाइलशीट के लोड दिखेंगे, पर फ़ाइल की सामग्री ले जाने वाला कोई HTTP संचार नहीं। यही तकनीकी प्रमाण है। फ़ाइल ब्राउज़र से बाहर नहीं जाती।
PDF को Word में कब बदलना चाहिए
कन्वर्ज़न की ज़रूरत कई रोज़मर्रा की स्थितियों में पैदा होती है। आपको PDF में अनुबंध या पत्र मिलता है और हस्ताक्षर से पहले कोई धारा बदलनी होती है। आप PDF में मिले टेम्पलेट — रिज़्यूमे, प्रस्ताव, रिपोर्ट — को शुरू से लिखे बिना दोबारा इस्तेमाल करना चाहते हैं। शिक्षक लेक्चर सामग्री PDF में साझा करते हैं और आप उद्धरण नोट्स में उतारना चाहते हैं। टीम कोई PDF रिपोर्ट भेजती है जिसका डेटा ऑफ़िस दस्तावेज़ में जोड़ना होता है। इन सब मामलों में Word में बदलने से दोबारा टाइप करने की तुलना में घंटों की बचत होती है, और टेबल, इमेज तथा लेआउट भी सुरक्षित रहते हैं। PdfXpo इस प्रक्रिया को तेज़, मुफ़्त और गोपनीय बनाता है — दस्तावेज़ को कहीं भेजे बिना।
हर वर्ड प्रोसेसर के अनुकूल
बनी .docx फ़ाइल OOXML मानक का पालन करती है और Microsoft Word (2010 या नया), LibreOffice Writer, Google Docs तथा Apple Pages (इम्पोर्ट) में बिना समस्या खुलती है। Windows और Mac तो हैं ही, Linux, Android और iOS पर भी। आप किसी एक सॉफ़्टवेयर से बँधे नहीं रहते। जहाँ सबसे सुविधाजनक हो वहाँ संपादित करें, और पूरा होने पर फिर से PDF में निर्यात कर लें। चूँकि कन्वर्ज़न रजिस्ट्रेशन या इंस्टॉल नहीं माँगता, पूरा प्रवाह — खोलें, बदलें, संपादित करें — शुरू से अंत तक कुछ ही सेकंड में पूरा होता है।
लोकल प्रोसेसिंग का मतलब सिर्फ़ गोपनीयता नहीं, गति भी क्यों है
जब PdfXpo कहता है "फ़ाइलें डिवाइस से बाहर नहीं जातीं," तो यह कोई नारा नहीं, बल्कि WebAssembly के उपयोग का सीधा परिणाम है। WebAssembly तकनीक PDF प्रोसेसिंग के कोड (C++ या Rust में लिखे) को सीधे ब्राउज़र के JavaScript इंजन में चलाती है। न कोई API फ़ाइल भेजने के लिए है, न कोई सर्वर उसे पाने के लिए। इसका एक व्यावहारिक लाभ गति भी है। क्लाउड टूल्स में फ़ाइल पहले सर्वर पर अपलोड होती है, वहाँ प्रोसेस होती है, फिर वापस डाउनलोड होती है। यह तीन-चरणीय प्रक्रिया, ख़ासकर बड़ी फ़ाइलों या धीमे कनेक्शन पर, कई मिनट ले सकती है। PdfXpo में अपलोड और डाउनलोड के चरण पूरी तरह ख़त्म हो जाते हैं, और कन्वर्ज़न वहीं शुरू होता है जहाँ फ़ाइल है — आपके डिवाइस की मेमोरी में। नतीजा एक ऐसा अनुभव है जो ज़्यादा निजी होने के साथ अक्सर ज़्यादा तेज़ भी है। बैंक स्टेटमेंट, अनुबंध, मेडिकल और सरकारी दस्तावेज़ जैसी संवेदनशील सामग्री के लिए यह एक अनिवार्य गारंटी है।
सर्वोत्तम कन्वर्ज़न परिणाम के लिए सुझाव
बेहतरीन परिणाम के लिए स्कैन के बजाय सॉफ़्टवेयर से बने मूल PDF को प्राथमिकता दें; इनमें ईमानदारी सबसे अधिक होती है। यदि दस्तावेज़ स्कैन है, तो कम से कम 200 DPI पर स्कैन करें और एक समान रोशनी का ध्यान रखें ताकि OCR हर अक्षर सही पहचाने। बहु-कॉलम दस्तावेज़ में बदलने के बाद कॉलम का क्रम जाँचें, और बहुत ग्राफ़िकल लेआउट को थोड़ा हाथ से समायोजन चाहिए हो सकता है। आख़िर में, बड़ी फ़ाइलें प्रोसेस करते समय टैब खुला रखें; कन्वर्ज़न लोकल रूप से आगे बढ़ता है और पेज बंद करने पर काम रुक जाता है। .docx मिलने पर इस्तेमाल से पहले एक नज़र डालकर फ़ॉर्मेटिंग की पुष्टि कर लें। ये छोटी आदतें अनुबंध हो, रिज़्यूमे हो या शोध-पत्र — लगभग हर दस्तावेज़ में पूर्णता के क़रीब परिणाम देती हैं। साथ ही, चूँकि कन्वर्ज़न पूरी तरह ब्राउज़र में होता है, आप वही दस्तावेज़ ऑफ़िस के कंप्यूटर, घर के लैपटॉप या सफ़र में मोबाइल जैसे कई डिवाइस पर बिना कुछ इंस्टॉल किए दोबारा प्रोसेस कर सकते हैं। बस एक आधुनिक ब्राउज़र और कुछ सेकंड चाहिए, और उपयोग की संख्या पर कोई सीमा न होना व्यवहार में बड़ा फ़र्क़ डालता है।
कोई रजिस्ट्रेशन नहीं। कोई वॉटरमार्क नहीं। कोई फ़ाइल सीमा नहीं। कोई क्लाउड अपलोड नहीं।
100% स्थानीय गोपनीयता
आपकी फ़ाइलें आपके कंप्यूटर से कभी बाहर नहीं जातीं
स्थानीय ब्राउज़र पावर
ब्राउज़र में त्वरित प्रोसेसिंग
सुरक्षित क्लाइंट-साइड प्रोसेसिंग
डेटा पूरी तरह से आपके ब्राउज़र में सुरक्षित रूप से संसाधित होता है
How to अरबी PDF को Word में बदलें – मुफ़्त — चरण दर चरण
PdfXpo खोलें: किसी भी आधुनिक ब्राउज़र में pdfxpo.com/pdf-to-word पर जाएँ — कोई इंस्टॉल नहीं, कोई अकाउंट नहीं, हर डिवाइस पर चलता है।
PDF अपलोड करें: PDF खींचें या "फ़ाइल चुनें" पर क्लिक करें। मूल और स्कैन दोनों, 200MB तक समर्थित।
कन्वर्ज़न शुरू करें: WebAssembly तकनीक फ़ाइल को ब्राउज़र में लोकल प्रोसेस करती है — डेटा कभी आपके डिवाइस से बाहर नहीं जाता।
Word फ़ाइल डाउनलोड करें: कुछ सेकंड में .docx तैयार। Word, LibreOffice या Google Docs में खोलकर स्वतंत्र रूप से संपादित करें।
PdfXpo क्यों?
PdfXpo WebAssembly तकनीक का उपयोग करता है – फ़ाइल सीधे ब्राउज़र में प्रोसेस होती है, कोई सर्वर ट्रांसमिशन नहीं। 100% मुफ़्त, असीमित, बिना रजिस्ट्रेशन।
सामान्य प्रश्न
क्या PdfXpo से स्कैन की गई PDF को Word में बदल सकता हूँ?
हाँ। PdfXpo में अंतर्निहित OCR इंजन स्कैन इमेज का विश्लेषण करके अक्षर पहचानता है और एडिटेबल Word दस्तावेज़ बनाता है। कम से कम 200 DPI के स्पष्ट स्कैन पर पहचान दर 95% से अधिक रहती है।
OCR किन भाषाओं को पहचानता है?
हिंदी, अंग्रेज़ी, अरबी, स्पैनिश, जर्मन सहित 30 से अधिक भाषाएँ। इंजन मुद्रित अक्षरों के लिए अनुकूलित है; हस्तलिखित दस्तावेज़ों में सटीकता घट जाती है।
सर्वोत्तम OCR परिणाम कैसे पाऊँ?
पेज की तस्वीर लेने के बजाय 200–300 DPI पर स्कैन करें और छाया या मुड़े पेज से बचें। स्पष्ट, अच्छे कंट्रास्ट वाला स्कैन कहीं बेहतर पहचान देता है।
क्या स्कैन की गई टेबल भी पुनर्निर्मित होती है?
हाँ। OCR के साथ मिलकर PdfXpo स्कैन की गई टेबल की हर सेल के अक्षर पहचानता है और संरचना को मूल Word टेबल के रूप में, कॉलम संरेखण बनाए रखते हुए पुनर्निर्मित करता है।
क्या मेरे स्कैन दस्तावेज़ OCR के लिए भेजे जाते हैं?
नहीं। OCR WebAssembly से लोकल चलता है। अक्सर संवेदनशील रहने वाले स्कैन दस्तावेज़ कभी सर्वर पर नहीं भेजे जाते। यह उन सेवाओं से अलग है जो OCR को क्लाउड के सशुल्क प्लान में रखती हैं।