Convertisseur OCR PDF en Word – gratuit en ligne
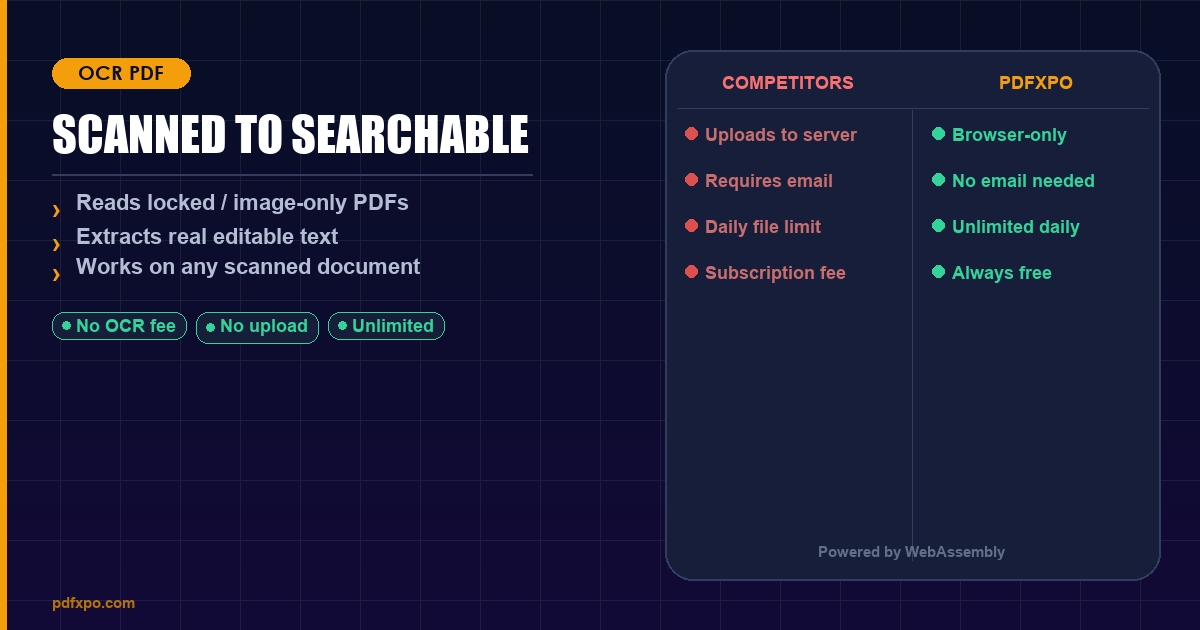
PDF scanné ou natif : pourquoi l'OCR change tout
Convertir un PDF scanné en Word est techniquement bien plus exigeant que convertir un PDF natif. La raison est simple : un PDF scanné ne contient aucune donnée textuelle — c'est une suite de photographies de pages. Le mot « facture » dans un scan n'est pas la lettre « f » suivie de « a », « c »… mais un ensemble de pixels qui ressemble à ces lettres. Pour rendre ce document modifiable, il faut la reconnaissance optique de caractères (OCR), qui analyse l'image et reconstruit le texte réel. PdfXpo intègre un moteur OCR avancé, gratuit et sans limite.
Comment fonctionne l'OCR de PdfXpo, en 4 phases
Phase 1 — Prétraitement de l'image
Chaque page est normalisée à une résolution homogène, le contraste est renforcé, le bruit de fond est réduit, et toute inclinaison du scan est corrigée. Un document numérisé de travers est automatiquement redressé.
Phase 2 — Identification des régions
La page est segmentée en zones — blocs de texte, images, tableaux. Chaque région est traitée séparément, ce qui évite de mélanger une légende d'image avec un paragraphe voisin.
Phase 3 — Reconnaissance des caractères
Pour chaque zone de texte, un modèle d'apprentissage automatique analyse la forme de chaque glyphe et l'associe au caractère Unicode correct. Le modèle a été entraîné sur des millions de pages dans plus de 100 langues.
Phase 4 — Reconstruction du texte
Les caractères reconnus sont assemblés en mots, les mots en lignes, les lignes en paragraphes — en préservant la structure d'origine du document.
Précision selon le type de document
Pour un texte français en police standard (Times New Roman, Arial, Calibri) numérisé à au moins 300 DPI, PdfXpo atteint une précision supérieure à 97 % — soit 2 à 3 mots potentiellement imparfaits sur 1 000. Les cas plus difficiles :
- Documents manuscrits : 50–80 % selon l'écriture (l'OCR est optimisé pour l'imprimé).
- Documents anciens (avant 1950) à l'encre pâlie : 60–85 %.
- Fonds colorés ou texturés : 70–90 %.
- Texte très petit (sous 8 pt) : précision réduite.
Arabe, hindi et écritures non latines
Les PDF en écriture arabe ou en devanagari (hindi) demandent un traitement particulier. Arabe : PdfXpo détecte automatiquement le sens d'écriture droite-à-gauche (RTL) et génère un document Word à l'orientation correcte ; les lettres arabes se liant différemment selon leur position, le modèle est entraîné à ces règles de liaison. Hindi/devanagari : l'écriture comporte une barre supérieure (« matra ») et des ligatures entre lettres — reconnues avec plus de 95 % de précision sur des documents imprimés nets.
Exigences minimales et préparation au scan
- Résolution : 200 DPI minimum, 300 DPI pour une qualité optimale. En dessous de 150 DPI, les caractères deviennent flous.
- Contraste : texte noir sur fond blanc donne les meilleurs résultats.
- Inclinaison : les scans jusqu'à ~5° sont redressés automatiquement ; au-delà, redressez manuellement avant conversion.
Si vous numérisez au smartphone, utilisez Microsoft Lens ou Adobe Scan (gratuits) : ces applications corrigent la perspective, optimisent le contraste et exportent un PDF propre — base idéale pour l'OCR.
Une fois le texte reconnu, PdfXpo reconstruit la structure — paragraphes, titres, et même les tableaux scannés redessinés en tableaux Word natifs. Et l'OCR s'exécute localement via WebAssembly : votre document scanné, souvent sensible, n'est jamais téléversé, là où Smallpdf et Adobe réservent l'OCR à leurs formules payantes en ligne.
Fondement technique : pourquoi convertir un PDF en Word est si difficile
Le format PDF a été créé par Adobe en 1993 avec une contrainte fondamentale du point de vue de la modification : un PDF ne stocke pas un document structuré, mais un ensemble d'instructions de tracé. Chaque élément — chaque lettre, chaque trait, chaque image — possède des coordonnées absolues (x, y) sur la page. Le mot « contrat » n'est pas un mot, mais huit glyphes distincts, chacun avec sa position, sa couleur et sa police.
Cette architecture rend le PDF idéal pour l'impression et l'affichage, mais problématique pour la conversion : il n'existe ni structure de « paragraphe », ni métadonnée de « tableau », ni hiérarchie de « titres ». Ce qui ressemble à un tableau ou à un titre doit être reconstruit par analyse géométrique.
L'architecture en 4 phases de PdfXpo
Phase 1 — Extraction complète des objets PDF : l'analyseur lit chaque flux de contenu du fichier et extrait tous les objets texte avec leurs attributs complets : coordonnées, nom de police, taille, espacement, couleur. En parallèle, les objets graphiques (lignes, rectangles, tracés) sont identifiés, et les images extraites avec leurs profils colorimétriques.
Phase 2 — Segmentation structurelle : l'algorithme regroupe les objets texte par proximité spatiale et caractéristiques typographiques en blocs logiques. Un titre est reconnu par une police plus grande, un espacement supérieur et sa position. Les tableaux sont identifiés par les segments de lignes qui se croisent pour former une grille. Les mises en page multicolonnes sont détectées par la séparation horizontale des colonnes.
Phase 3 — Mappage sémantique : chaque bloc structurel est associé à un élément Word : titres → styles Titre 1/2/3 ; éléments de liste → listes Word numérotées ou à puces ; tableaux → objets tableaux Word natifs ; notes de bas de page → objets notes OOXML correctement liés ; images → objets image ancrés.
Phase 4 — Génération du document OOXML : un fichier .docx conforme au standard OOXML (ISO/IEC 29500) est produit. Les dimensions de page, marges, en-têtes et pieds de page sont repris de l'original. Les polices indisponibles sont remplacées par des polices métriquement équivalentes.
Mesures : ce que PdfXpo garantit
PdfXpo face aux alternatives
La différence décisive : PdfXpo ne transmet aucune donnée de fichier à un serveur. Avec Adobe, Smallpdf et iLovePDF, vos documents quittent votre appareil — une réalité juridique qui compte pour les documents professionnels et personnels sensibles.
Étape par étape : convertir un PDF en Word avec PdfXpo
Étape 1 — Ouvrir le navigateur : rendez-vous sur pdfxpo.com/pdf-to-word dans Chrome, Edge, Firefox ou Safari. Aucune installation, aucun compte, aucune extension.
Étape 2 — Charger le fichier : glissez-déposez le PDF dans la zone d'import ou cliquez sur « Sélectionner un fichier ». Jusqu'à 200 Mo, sans limite quotidienne.
Étape 3 — Attendre la conversion : le traitement s'exécute localement. 10 pages : 5–15 secondes. 50 pages : 20–40 secondes. 200 pages : 1–3 minutes. Pages scannées (OCR) : 2 à 4 fois plus long.
Étape 4 — Télécharger et ouvrir : le fichier .docx est enregistré dans vos téléchargements. Ouvrez-le dans Microsoft Word 2010+, LibreOffice Writer ou Google Docs.
Confidentialité : une garantie techniquement vérifiable
WebAssembly est un environnement d'exécution dans le navigateur qui lance du code natif dans une sandbox isolée. L'algorithme de conversion de PdfXpo s'exécute comme un module WebAssembly directement dans la mémoire de votre navigateur — aucun serveur n'intervient.
Vérification en 30 secondes : ouvrez les outils de développement (F12), onglet « Réseau », et chargez un PDF dans PdfXpo. Pendant la conversion, vous verrez se charger les scripts et les feuilles de style — mais aucune requête HTTP ne transporte le contenu de votre fichier. C'est la preuve technique : votre fichier ne quitte pas le navigateur.
Conseils pour une conversion réussie
Pour obtenir le meilleur résultat, privilégiez un PDF natif (créé depuis un logiciel) plutôt qu'un scan : la fidélité y est maximale. Si votre document est scanné, numérisez-le à au moins 200 DPI et veillez à un éclairage uniforme afin que l'OCR reconnaisse correctement chaque caractère. Pour les documents à plusieurs colonnes, vérifiez l'ordre des colonnes après conversion ; pour les mises en page très graphiques, un léger ajustement manuel peut parfois être nécessaire. Enfin, gardez l'onglet ouvert pendant le traitement des gros fichiers : la conversion progresse localement, et fermer la page interromprait l'opération. Une fois le fichier .docx obtenu, ouvrez-le et parcourez-le rapidement pour valider la mise en forme avant de l'utiliser.
Sans inscription. Sans filigrane. Sans limite de fichier. Sans téléversement vers le cloud.
Confidentialité 100% locale
Vos fichiers ne quittent jamais votre ordinateur
Puissance du navigateur local
Traitement instantané dans le navigateur
Traitement côté client sécurisé
Données traitées localement dans votre navigateur
How to Convertisseur OCR PDF en Word – gratuit en ligne — Étape par étape
Ouvrir PdfXpo: Rendez-vous sur pdfxpo.com/pdf-to-word dans un navigateur moderne — aucune installation, aucun compte, fonctionne sur tous les appareils.
Importer le PDF: Glissez-déposez votre PDF ou cliquez sur 'Sélectionner un fichier'. Les PDF natifs et scannés sont acceptés, jusqu'à 200 Mo.
Lancer la conversion: La technologie WebAssembly traite votre fichier localement dans le navigateur — vos données ne quittent jamais votre appareil.
Télécharger le fichier Word: En quelques secondes, le .docx est prêt. Ouvrez-le dans Word, LibreOffice ou Google Docs et modifiez-le librement.
Pourquoi choisir PdfXpo ?
PdfXpo utilise la technologie WebAssembly – vos fichiers sont traités directement dans votre navigateur, sans envoi sur un serveur. 100% gratuit, illimité, sans inscription.
Questions fréquentes
Peut-on convertir un PDF scanné en Word avec PdfXpo ?
Oui. PdfXpo intègre un moteur OCR (reconnaissance optique de caractères) qui analyse l'image scannée, identifie le texte et crée un document Word modifiable. Pour un scan net d'au moins 200 DPI, le taux de reconnaissance dépasse 95 %.
Quelles langues l'OCR reconnaît-il ?
Plus de 30 langues, dont le français avec ses accents (é, è, à, ç), l'anglais, l'espagnol, l'allemand, l'arabe et l'hindi. Le moteur est optimisé pour le texte imprimé ; les documents manuscrits donnent une précision moindre.
Comment obtenir le meilleur résultat OCR ?
Numérisez à 200–300 DPI plutôt que de photographier la page, évitez les ombres et les pages gondolées. Un scan net et bien contrasté donne une reconnaissance nettement supérieure.
Les tableaux scannés sont-ils reconstruits ?
Oui. Combiné à l'OCR, PdfXpo reconnaît le texte de chaque cellule d'un tableau scanné et reconstruit la structure en tableau Word natif, préservant l'alignement des colonnes.
Mon document scanné est-il téléversé pour l'OCR ?
Non. L'OCR s'exécute localement via WebAssembly. Votre document scanné — souvent une pièce sensible — n'est jamais envoyé sur un serveur, contrairement aux services qui réservent l'OCR à leurs offres payantes dans le cloud.